Aim
To introduce methods for exploring clustering in spatial data
Content
This post provides an introduction to methods for exploring clustering in different types of spatial data. The approaches will be explored together in R, followed by an opportunity to adapt the code and run the analysis yourself.
Datasets
- Malaria point prevalence data at the village level from Burkina Faso
- Leukemia data at the census tract level from New York State
- Malaria case event data and population controls from northern Namibia
First we will attach the libraries used for visualization.
library(rgdal)
library(raster)
library(ggplot2)
library(spatstat)
library(plotrix)
library(fields)
library(leaflet)
library(maptools)
library(RColorBrewer)
library(lattice)
library(geoR)
library(plotrix)
library(car) # contains a function for logistic transformation (log odds) to make more normal
These libraries are for spatial data management and point process analysis.
library(sp)
# Moran's I and spatial dependencies
library(spdep) # Spatial Dependence: Weighting Schemes, Statistics and Models
library(ape) # Analyses of Phylogenetics and Evolution
library(pgirmess) # Data Analysis in Ecology
# Libraries for point processes
library(spatstat)
library(splancs) # K-function
library(smacpod) # Spatial scanning statistic
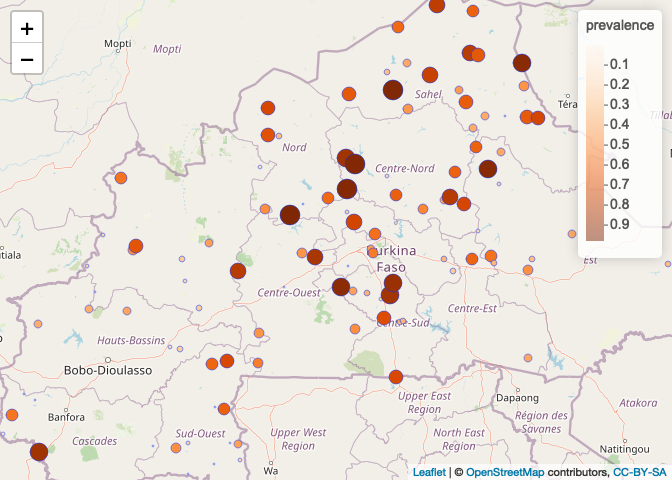
We’re going to load in some malaria data from Burkina Faso and visualize it using Leaflet to see if we can initially assess if there may be evidence of spatial clustering. What do you think?
# Open BF malaria data
BF_malaria_data <- read.csv("https://raw.githubusercontent.com/HughSt/HughSt.github.io/master/course_materials/week4/Lab_files/BF_malaria_data.csv",header=T)
BF_Adm_1 <- raster::getData("GADM", country="BFA", level=1)
proj4string(BF_Adm_1) <- CRS('+proj=longlat +datum=WGS84 +no_defs +ellps=WGS84 +towgs84=0,0,0 ')
## Warning in showSRID(uprojargs, format = "PROJ", multiline = "NO"): Discarded datum WGS_1984 in CRS definition,
## but +towgs84= values preserved
## Warning in proj4string(obj): CRS object has comment, which is lost in output
## Warning in `proj4string<-`(`*tmp*`, value = new("CRS", projargs = "+proj=longlat +ellps=WGS84 +towgs84=0,0,0,0,0,0,0 +no_defs")): A new CRS was assigned to an object with an existing CRS:
## +proj=longlat +datum=WGS84 +no_defs
## without reprojecting.
## For reprojection, use function spTransform
# Calculate prevalence
BF_malaria_data$prevalence <- BF_malaria_data$positives / BF_malaria_data$examined
# What do the data look like - do you see evidence of spatial clustering?
pal = colorNumeric("Oranges", BF_malaria_data$prevalence)
leaflet(BF_malaria_data) %>% addTiles() %>% addCircleMarkers(~longitude, ~latitude, fillOpacity=1,
fillColor= ~pal(prevalence), radius=~prevalence*10, stroke=TRUE, weight=1) %>%
addLegend(pal = pal, values = ~prevalence)
Part I: Testing for spatial autocorrelation in point-level data
Global spatial autocorrelation
In this section we’re going to look at some more formal statistical tests of global spatial autocorrelation. We’ll look at two general ways of doing this: using ‘Moran’s I’ and using correlograms. These can each be done using multiple different packages in R.
Approach 1: Calculate Moran’s I using a distance based matrix
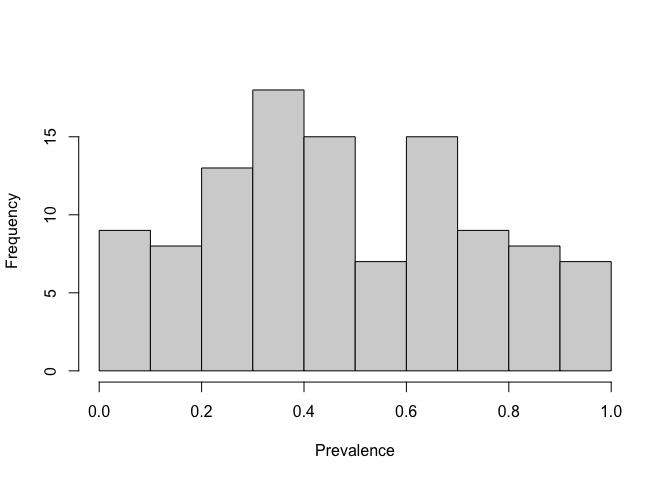
First we will look at the distribution of the prevalence data to see if they are close to normally distributed. If the are very skewed, we will need to transform them because the Moran’s I test produces a comparison to the normal distribution. Here, we will use the logit transformation to produce a more normal distribution. Then we will calculate the distance between each of the points and use the inverse of the distance matrix to produce a matrix of weights that we will use to calculate Moran’s I.
hist(BF_malaria_data$prevalence, xlab = "Prevalence", main = "")
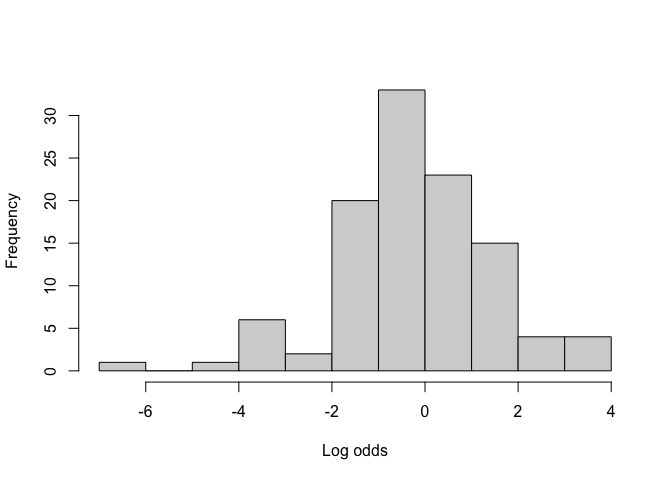
BF_malaria_data$log_odds <- logit(BF_malaria_data$prevalence)
hist(BF_malaria_data$log_odds, xlab = "Log odds", main = "")
# Generate a distance matrix
BF.dists <- as.matrix(dist(cbind(BF_malaria_data$longitude, BF_malaria_data$latitude)))
dim(BF.dists) # 109 x 109 matrix of distance between all sets of points
## [1] 109 109
# Take the inverse of the matrix values so that closer values have a larger weight and vs vs
BF.dists.inv <- 1/BF.dists
diag(BF.dists.inv) <- 0 # replace the diagonal values with zero
# Computes Moran's I autocorrelation coefficient of x giving a matrix of weights (here based on distance)
Moran.I(BF_malaria_data$log_odds, BF.dists.inv) # from the "ape" package
## $observed
## [1] 0.0666352
##
## $expected
## [1] -0.009259259
##
## $sd
## [1] 0.01639855
##
## $p.value
## [1] 3.690017e-06
Approach 2: Create a correlogram to explore Moran’s I over different spatial lags. The “pgirmess” package requires spdep (which also has correlogram options) but is much simplier and user-friendly.
# Calculate the maximum distance between points
maxDist<-max(dist(cbind(BF_malaria_data$longitude, BF_malaria_data$latitude)))
maxDist
## [1] 7.534414
xy=cbind(BF_malaria_data$longitude, BF_malaria_data$latitude)
pgi.cor <- correlog(coords=xy, z=BF_malaria_data$log_odds, method="Moran", nbclass=10) # "pgirmess" package
# coords = xy cordinates, z= vector of values at each location and nbclass = the number of bins
plot(pgi.cor) # statistically significant values (p<0.05) are plotted in red
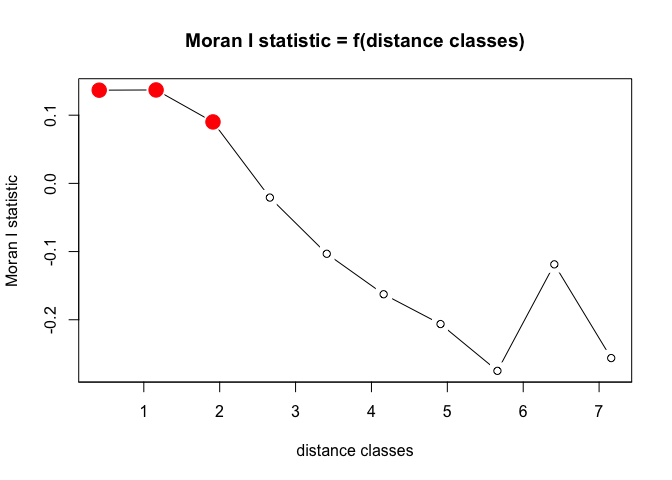
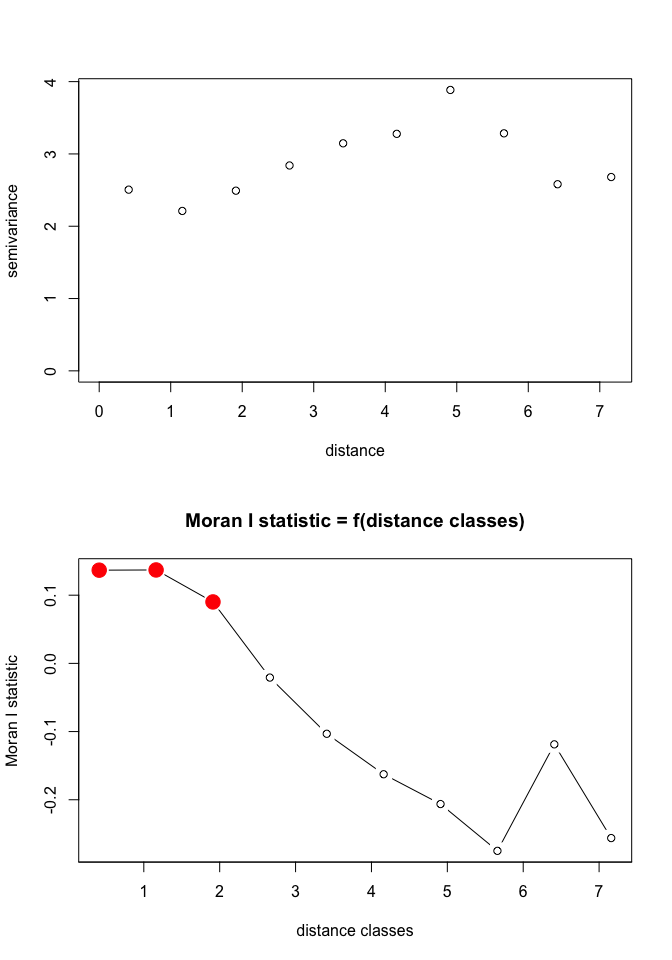
pgi.cor # distclass is midpoint for the bin
## Moran I statistic
## dist.class coef p.value n
## [1,] 0.4121237 0.13669304 6.435709e-04 1092
## [2,] 1.1618390 0.13700359 3.059924e-06 2176
## [3,] 1.9115538 0.09009855 2.482029e-05 2680
## [4,] 2.6612685 -0.02082828 6.589705e-01 2172
## [5,] 3.4109833 -0.10323722 9.946353e-01 1376
## [6,] 4.1606981 -0.16259353 9.997622e-01 1146
## [7,] 4.9104129 -0.20629178 9.991684e-01 662
## [8,] 5.6601277 -0.27492632 9.990240e-01 320
## [9,] 6.4098425 -0.11874035 7.536360e-01 128
## [10,] 7.1595572 -0.25618534 7.320096e-01 20
Based on the correlogram, over what spatial lags are there evidence for spatial autocorrelation? Is this clustering positive or negative?
Compare the correlogram to the results from a semivariogram approach:
BF_malaria_data_geo<-as.geodata(BF_malaria_data[,c("longitude","latitude","log_odds")])
# Generate and plot a binned variogram (10 bins) NB: have made for full max distance (even though likely inaccurate) for comparison
Vario<-variog(BF_malaria_data_geo,max.dist=7.53,uvec=seq(0.4121237,7.1595572,l=10))
par(mfrow=c(2,1))
plot(Vario)
plot(pgi.cor)
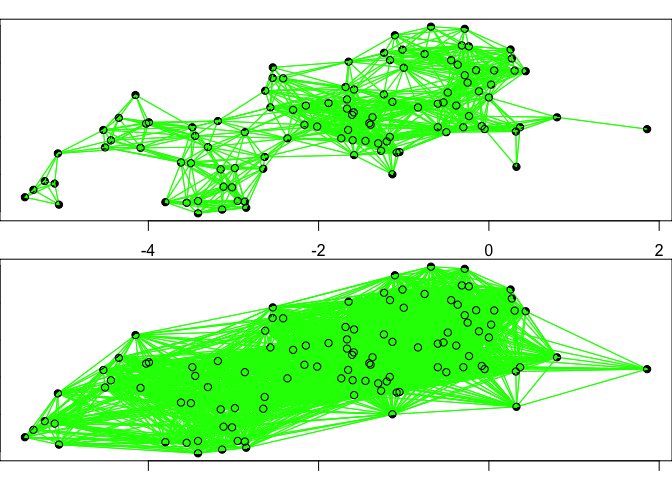
Approach 3: Calculate Moran’s I using a binary distance matrix. For this approach, we are going to create sets of ‘neighbors’ based upon their proximity. This approach can be used with point data but is especially useful for areal data, as we will see shortly.
For this approach, you will need to consider what is a sensible distance to classify points as neighbors. Considerations might include the scale of analysis and the distribution of points. In the comparison of different neighboring structures, you can see that increasing the distance within which one is considered a neighbor dramatically increases the overall number of neighbor linkages.
coords<-coordinates(xy) # set spatial coordinates to create a spatial object
IDs<-row.names(as.data.frame(coords))
# In this approach, we chose a distance d such that pairs of points with distances less than
# d are neighbors and those further apart are not.
Neigh_nb<-knn2nb(knearneigh(coords, k=1, longlat = TRUE), row.names=IDs) # using the "spdep" package
# assigns at least one neighbor to each and calculates the distances between
dsts<-unlist(nbdists(Neigh_nb,coords)) # returns the distance between nearest neighbors for each point
summary(dsts)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.03727 0.12693 0.19004 0.22742 0.27488 1.10524
max_1nn<-max(dsts)
max_1nn # maximum distance to provide at least one neighbor to each point
## [1] 1.10524
# We create different neighbor structures based upon distance
Neigh_kd1<-dnearneigh(coords,d1=0, d2=max_1nn, row.names=IDs) # neighbors within maximum distance
Neigh_kd2<-dnearneigh(coords,d1=0, d2=2*max_1nn, row.names=IDs) # neighbors within 2X maximum distance
nb_1<-list(d1=Neigh_kd1, d2=Neigh_kd2) # list of neighbor structures
sapply(nb_1, function(x) is.symmetric.nb(x, verbose=F, force=T))
## d1 d2
## TRUE TRUE
# Checks for symmetry (i.e. if i is a neighbor of j, then j is a neighbor of i). Does not always hold for k-nearest neighbours
sapply(nb_1, function(x) n.comp.nb(x)$nc)
## d1 d2
## 1 1
# Number of disjoint connected subgraphs
# Plot neighbors comparing the two distances
par(mfrow=c(2,1), mar= c(1, 0, 1, 0))
plot(xy, pch=16)
plot(Neigh_kd1, coords, col="green",add=T)
plot(xy, pch=16)
plot(Neigh_kd2, coords,col="green", add=T)
To run a spatial test for clustering, we need to assign weights to the neighbor list. We will use the neighbor structure with all neighbors within the maximum neighbor distance between any two points.
#assign weights;
weights<-nb2listw(Neigh_kd1, style="W") # row standardized binary weights, using minimum distance for one neighbor
weights # "B" is simplest binary weights
## Characteristics of weights list object:
## Neighbour list object:
## Number of regions: 109
## Number of nonzero links: 1914
## Percentage nonzero weights: 16.10976
## Average number of links: 17.55963
##
## Weights style: W
## Weights constants summary:
## n nn S0 S1 S2
## W 109 11881 109 16.44475 442.0046
Using this weights matrix, we can now run the Moran’s I test on the logit transformed prevalence using the neighborhood matrix. How do the results compare to other approaches?
moran.test(BF_malaria_data$log_odds , listw=weights) #using row standardised weights
##
## Moran I test under randomisation
##
## data: BF_malaria_data$log_odds
## weights: weights
##
## Moran I statistic standard deviate = 4.7332, p-value = 1.105e-06
## alternative hypothesis: greater
## sample estimates:
## Moran I statistic Expectation Variance
## 0.154300895 -0.009259259 0.001194126
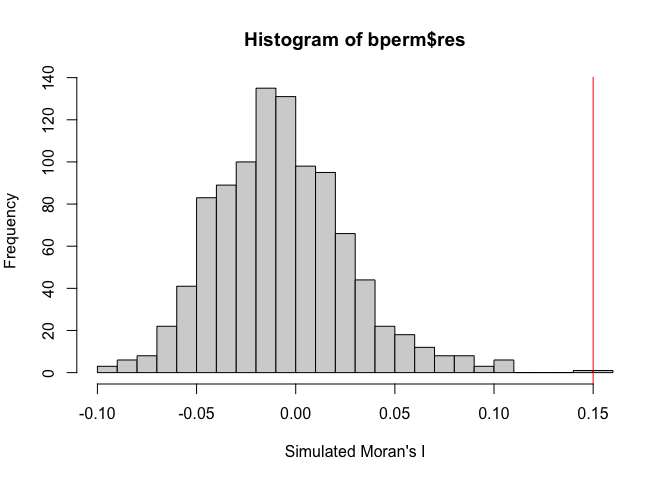
We can also use a simulation approach: we simulate the test statistic using random permutations of BF_malaria_data$log_odds so that the values are randomly assigned to locations and the statistic is computed nsim times; we compare the observed statistic to the distribution. What do you conclude about evidence for spatial autocorrelation?
set.seed(1234)
bperm<-moran.mc(BF_malaria_data$log_odds , listw=weights,nsim=999)
bperm
##
## Monte-Carlo simulation of Moran I
##
## data: BF_malaria_data$log_odds
## weights: weights
## number of simulations + 1: 1000
##
## statistic = 0.1543, observed rank = 1000, p-value = 0.001
## alternative hypothesis: greater
#statistic = 0.15, observed rank = 1000, p-value = 0.001
# Plot simulated test statistics
par(mfrow=c(1,1), mar= c(5, 4, 4, 2))
hist(bperm$res, freq=T, breaks=20, xlab="Simulated Moran's I")
abline(v=0.15, col="red")
We can now also take a look at running Moran’s I for areal data (polygons), using a dataset on leukemia from New York (Turnbull et al 1990). We will also use these data later in the course in week 7.
nydata <- rgdal::readOGR("https://raw.githubusercontent.com/HughSt/HughSt.github.io/master/course_materials/week7/Lab_files/nydata.geojson")
## OGR data source with driver: GeoJSON
## Source: "https://raw.githubusercontent.com/HughSt/HughSt.github.io/master/course_materials/week7/Lab_files/nydata.geojson", layer: "nydata"
## with 281 features
## It has 17 fields
#lets take a look at the data
head(nydata@data)
## AREANAME AREAKEY X Y POP8 TRACTCAS PROPCAS
## 0 Binghamton city 36007000100 4.069397 -67.3533 3540 3.08 0.000870
## 1 Binghamton city 36007000200 4.639371 -66.8619 3560 4.08 0.001146
## 2 Binghamton city 36007000300 5.709063 -66.9775 3739 1.09 0.000292
## 3 Binghamton city 36007000400 7.613831 -65.9958 2784 1.07 0.000384
## 4 Binghamton city 36007000500 7.315968 -67.3183 2571 3.06 0.001190
## 5 Binghamton city 36007000600 8.558753 -66.9344 2729 1.06 0.000388
## PCTOWNHOME PCTAGE65P Z AVGIDIST PEXPOSURE Cases Xm Ym
## 0 0.3277311 0.1466102 0.14197 0.2373852 3.167099 3.08284 4069.397 -67353.3
## 1 0.4268293 0.2351124 0.35555 0.2087413 3.038511 4.08331 4639.371 -66861.9
## 2 0.3377396 0.1380048 -0.58165 0.1708548 2.838229 1.08750 5709.063 -66977.5
## 3 0.4616048 0.1188937 -0.29634 0.1406045 2.643366 1.06515 7613.831 -65995.8
## 4 0.1924370 0.1415791 0.45689 0.1577753 2.758587 3.06017 7315.968 -67318.3
## 5 0.3651786 0.1410773 -0.28123 0.1726033 2.848411 1.06386 8558.753 -66934.4
## Xshift Yshift
## 0 423391.0 4661502
## 1 423961.0 4661993
## 2 425030.6 4661878
## 3 426935.4 4662859
## 4 426637.5 4661537
## 5 427880.3 4661921
For now, with this dataset we are only interested in seeing if there is global clustering in the area-level case incidence. In the dataset we find a ‘Cases’ variable that gives the estimated number of cases per area. We need to also consider the population in each area however, because areas with higher populations are more likely to have more cases just due to population size. So we will first create an incidence variable to normalize the case data by population size.
nydata$inc_per_1000 <- (nydata$Cases / nydata$POP8) * 1000
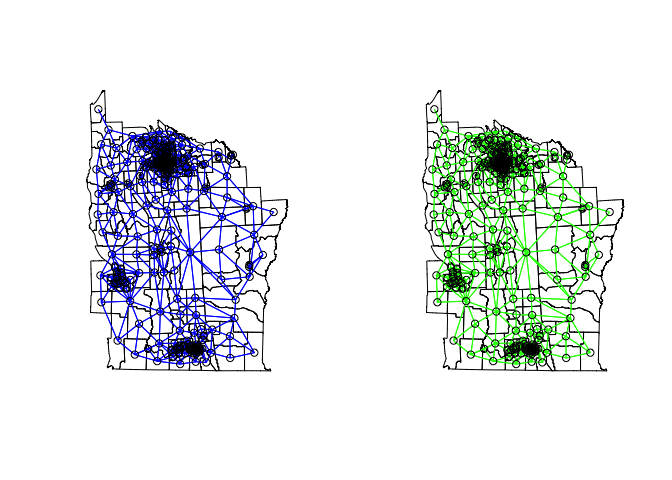
As these are areas and not points, we will not use distance to define the neighbors, but rather which polygons are directly touching one another along a boundary or boundary point.
# Contiguity neighbors - all that share a boundary point
nydata_nb <- poly2nb(nydata) #queen contiguity
nydata_nbr <- poly2nb(nydata,queen=F) #rook contiguity
#coordinates
coords_ny<-coordinates(nydata)
#view and compare the neighbors
par(mfrow=c(1,2))
plot(nydata)
plot(nydata_nb,coords_ny,col="blue",add=T)
plot(nydata)
plot(nydata_nbr,coords_ny,col="green",add=T)
As above, we then set the weights for the neighbor matrix. The default is row standardized (each row sums to one), or binary, where neighbors are 1 and 0 otherwise.
##set weights - contiguity
#weights style W - row standardized
nydata_w<-nb2listw(nydata_nb)
nydata_w
## Characteristics of weights list object:
## Neighbour list object:
## Number of regions: 281
## Number of nonzero links: 1624
## Percentage nonzero weights: 2.056712
## Average number of links: 5.779359
##
## Weights style: W
## Weights constants summary:
## n nn S0 S1 S2
## W 281 78961 281 106.6125 1164.157
#weights style B - binary
nydata_wB<-nb2listw(nydata_nb,style="B")
nydata_wB
## Characteristics of weights list object:
## Neighbour list object:
## Number of regions: 281
## Number of nonzero links: 1624
## Percentage nonzero weights: 2.056712
## Average number of links: 5.779359
##
## Weights style: B
## Weights constants summary:
## n nn S0 S1 S2
## B 281 78961 1624 3248 41440
Based on this weights matrix, we can now do an initial check of spatial autocorrelation in the data. What do you conclude? We will return to this dataset in week 7.
##moran's tests of global spatial autocorrelation
moran.test(nydata$inc_per_1000,listw=nydata_w) #using row standardized
##
## Moran I test under randomisation
##
## data: nydata$inc_per_1000
## weights: nydata_w
##
## Moran I statistic standard deviate = 1.8649, p-value = 0.0311
## alternative hypothesis: greater
## sample estimates:
## Moran I statistic Expectation Variance
## 0.060405798 -0.003571429 0.001176865
Local spatial autocorrelation
The above approaches examined evidence for global spatial autorrelation. Now we’re going to look at local measures of clustering. One way to do this is using ‘Local Moran’s I’, which we will illustrate using the point-level data from Burkina Faso.
# First calculate the local Moran's I around each point based on the spatial weights object (binary based on at least one neighbor)
I <-localmoran(BF_malaria_data$log_odds, weights) # "spdep" package
# Print 'LISA' for each point
Coef<-printCoefmat(data.frame(I[IDs,], row.names=row.names(coords),
check.names=FALSE))
## Ii E.Ii Var.Ii Z.Ii Pr(z > 0)
## [1,] 0.1812462 -0.0092593 0.2357816 0.3923 0.347407
## [2,] -0.1281931 -0.0092593 0.1868702 -0.2751 0.608391
## [3,] 0.1775977 -0.0092593 0.1868702 0.4323 0.332778
## [4,] 0.1609526 -0.0092593 0.1868702 0.3937 0.346883
## [5,] 0.1415001 -0.0092593 0.1309714 0.4166 0.338494
## [6,] -0.9356236 -0.0092593 0.2357816 -1.9078 0.971790
## [7,] 0.2048078 -0.0092593 0.0890473 0.7174 0.236575
## [8,] 0.1032625 -0.0092593 0.0890473 0.3771 0.353059
## [9,] 0.6486575 -0.0092593 0.0890473 2.2048 0.013736 *
## [10,] 0.2287016 -0.0092593 0.0999165 0.7528 0.225781
## [11,] -0.0632071 -0.0092593 0.1868702 -0.1248 0.549658
## [12,] 0.0528866 -0.0092593 0.0664728 0.2410 0.404762
## [13,] -0.0312340 -0.0092593 0.0801543 -0.0776 0.530934
## [14,] -0.2745658 -0.0092593 0.0801543 -0.9371 0.825646
## [15,] 1.8953445 -0.0092593 0.0727435 7.0617 8.225e-13 ***
## [16,] 0.3782145 -0.0092593 0.0523637 1.6933 0.045202 *
## [17,] -0.0770823 -0.0092593 0.0664728 -0.2631 0.603748
## [18,] 0.1661593 -0.0092593 0.0523637 0.7666 0.221664
## [19,] 0.1462169 -0.0092593 0.0610979 0.6290 0.264674
## [20,] 0.2192834 -0.0092593 0.0487673 1.0349 0.150355
## [21,] 2.6115192 -0.0092593 0.0999165 8.2911 < 2.2e-16 ***
## [22,] 0.6084835 -0.0092593 0.0664728 2.3960 0.008288 **
## [23,] 0.1432275 -0.0092593 0.0564396 0.6419 0.260482
## [24,] 0.0027566 -0.0092593 0.0801543 0.0424 0.483073
## [25,] -0.2709034 -0.0092593 0.0455704 -1.2257 0.889836
## [26,] 2.1542250 -0.0092593 0.0890473 7.2501 2.082e-13 ***
## [27,] 1.6953501 -0.0092593 0.0523637 7.4492 4.695e-14 ***
## [28,] -0.4303787 -0.0092593 0.0564396 -1.7726 0.961853
## [29,] -0.4505613 -0.0092593 0.0523637 -1.9285 0.973104
## [30,] 2.4251511 -0.0092593 0.0727435 9.0260 < 2.2e-16 ***
## [31,] 0.0925837 -0.0092593 0.0727435 0.3776 0.352863
## [32,] -0.0311741 -0.0092593 0.0564396 -0.0922 0.536749
## [33,] 0.6410560 -0.0092593 0.0727435 2.4112 0.007951 **
## [34,] -0.1343683 -0.0092593 0.0664728 -0.4853 0.686251
## [35,] -0.0018818 -0.0092593 0.0564396 0.0311 0.487613
## [36,] -0.5023862 -0.0092593 0.0664728 -1.9127 0.972104
## [37,] 0.0141531 -0.0092593 0.0401358 0.1169 0.453484
## [38,] 0.4099818 -0.0092593 0.0801543 1.4808 0.069328 .
## [39,] 0.0164268 -0.0092593 0.1309714 0.0710 0.471709
## [40,] -0.2754463 -0.0092593 0.0801543 -0.9402 0.826444
## [41,] -0.1260415 -0.0092593 0.0319839 -0.6530 0.743121
## [42,] 0.3626538 -0.0092593 0.0337561 2.0243 0.021472 *
## [43,] 0.0017248 -0.0092593 0.0303535 0.0630 0.474865
## [44,] -0.3378536 -0.0092593 0.0303535 -1.8861 0.970357
## [45,] 0.3010447 -0.0092593 0.0303535 1.7811 0.037450 *
## [46,] 0.0671954 -0.0092593 0.0303535 0.4388 0.330391
## [47,] 0.1493807 -0.0092593 0.0319839 0.8870 0.187527
## [48,] 0.4352201 -0.0092593 0.0337561 2.4192 0.007777 **
## [49,] -0.1673619 -0.0092593 0.0274551 -0.9542 0.830002
## [50,] 0.4136893 -0.0092593 0.0288486 2.4901 0.006384 **
## [51,] -0.5022262 -0.0092593 0.0249564 -3.1205 0.999097
## [52,] 0.3696506 -0.0092593 0.0664728 1.4697 0.070828 .
## [53,] -0.3096059 -0.0092593 0.0249564 -1.9012 0.971363
## [54,] -0.0141401 -0.0092593 0.0303535 -0.0280 0.511175
## [55,] 0.2041696 -0.0092593 0.0249564 1.3510 0.088344 .
## [56,] 0.0030584 -0.0092593 0.0427101 0.0596 0.476236
## [57,] 0.4841543 -0.0092593 0.0288486 2.9050 0.001836 **
## [58,] -0.0133199 -0.0092593 0.0303535 -0.0233 0.509297
## [59,] -0.0133688 -0.0092593 0.0217940 -0.0278 0.511104
## [60,] 0.0531181 -0.0092593 0.0208677 0.4318 0.332941
## [61,] 0.1046654 -0.0092593 0.0208677 0.7886 0.215160
## [62,] -0.0494912 -0.0092593 0.0319839 -0.2250 0.588995
## [63,] 0.0720471 -0.0092593 0.0427101 0.3934 0.347004
## [64,] -0.2179338 -0.0092593 0.0319839 -1.1668 0.878358
## [65,] -0.2961410 -0.0092593 0.0664728 -1.1127 0.867083
## [66,] 0.0955202 -0.0092593 0.0319839 0.5859 0.278977
## [67,] 0.0459319 -0.0092593 0.0288486 0.3249 0.372612
## [68,] 0.9354163 -0.0092593 0.0455704 4.4253 4.816e-06 ***
## [69,] 0.1305499 -0.0092593 0.0999165 0.4423 0.329136
## [70,] 0.1286256 -0.0092593 0.0261611 0.8525 0.196972
## [71,] 0.2177453 -0.0092593 0.0727435 0.8417 0.199989
## [72,] -0.0522963 -0.0092593 0.0487673 -0.1949 0.577258
## [73,] -0.0428396 -0.0092593 0.0487673 -0.1521 0.560431
## [74,] -0.0743488 -0.0092593 0.0610979 -0.2633 0.603851
## [75,] 0.0024038 -0.0092593 0.0319839 0.0652 0.474001
## [76,] 0.0305890 -0.0092593 0.0208677 0.2758 0.391332
## [77,] 0.3382428 -0.0092593 0.0427101 1.6815 0.046335 *
## [78,] 0.5167263 -0.0092593 0.0890473 1.7626 0.038981 *
## [79,] -0.0213228 -0.0092593 0.0238320 -0.0781 0.531143
## [80,] -0.0356182 -0.0092593 0.0249564 -0.1669 0.566258
## [81,] 0.0775887 -0.0092593 0.0303535 0.4985 0.309070
## [82,] -0.0709209 -0.0092593 0.0319839 -0.3448 0.634872
## [83,] 0.1307050 -0.0092593 0.0274551 0.8447 0.199137
## [84,] -0.0128502 -0.0092593 0.0337561 -0.0195 0.507797
## [85,] 0.0290511 -0.0092593 0.0337561 0.2085 0.417413
## [86,] 0.2235697 -0.0092593 0.0288486 1.3708 0.085218 .
## [87,] 0.3949081 -0.0092593 0.0427101 1.9557 0.025252 *
## [88,] 0.0760215 -0.0092593 0.0356893 0.4514 0.325843
## [89,] 0.2764567 -0.0092593 0.0890473 0.9575 0.169166
## [90,] -0.0723277 -0.0092593 0.0303535 -0.3620 0.641324
## [91,] 0.1712432 -0.0092593 0.0303535 1.0360 0.150091
## [92,] 0.2227674 -0.0092593 0.0401358 1.1582 0.123398
## [93,] -0.1641587 -0.0092593 0.0401358 -0.7732 0.780294
## [94,] -0.0853343 -0.0092593 0.0356893 -0.4027 0.656413
## [95,] 0.1452289 -0.0092593 0.0319839 0.8638 0.193840
## [96,] 0.0349493 -0.0092593 0.0564396 0.1861 0.426189
## [97,] -0.0377275 -0.0092593 0.0523637 -0.1244 0.549504
## [98,] -0.0832743 -0.0092593 0.0303535 -0.4248 0.664520
## [99,] -0.0451134 -0.0092593 0.0427101 -0.1735 0.568867
## [100,] -0.5362934 -0.0092593 0.0427101 -2.5502 0.994617
## [101,] 0.4692542 -0.0092593 0.0610979 1.9359 0.026440 *
## [102,] 0.0136534 -0.0092593 0.0523637 0.1001 0.460121
## [103,] 0.1868468 -0.0092593 0.0564396 0.8255 0.204554
## [104,] -0.0086863 -0.0092593 0.0801543 0.0020 0.499193
## [105,] 0.0292903 -0.0092593 0.3173007 0.0684 0.472719
## [106,] -0.0203350 -0.0092593 0.0727435 -0.0411 0.516378
## [107,] 0.2580123 -0.0092593 0.0564396 1.1250 0.130290
## [108,] 0.0493837 -0.0092593 0.1309714 0.1620 0.435636
## [109,] 0.0645350 -0.0092593 0.9694534 0.0749 0.470128
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# Plot the spatial data against its spatially lagged values (the weighted mean of its neighbors)
nci<-moran.plot(BF_malaria_data$log_odds, listw=weights,
xlab="Log prevalence", ylab="Spatially lagged log prev", labels=T, pch=16, col="grey")
text(c(3,3, -5,-5),c(0.9, -1.9,0.9,-1.9), c("High-High", "High-Low", "Low-High", "Low-Low"), cex=0.8)
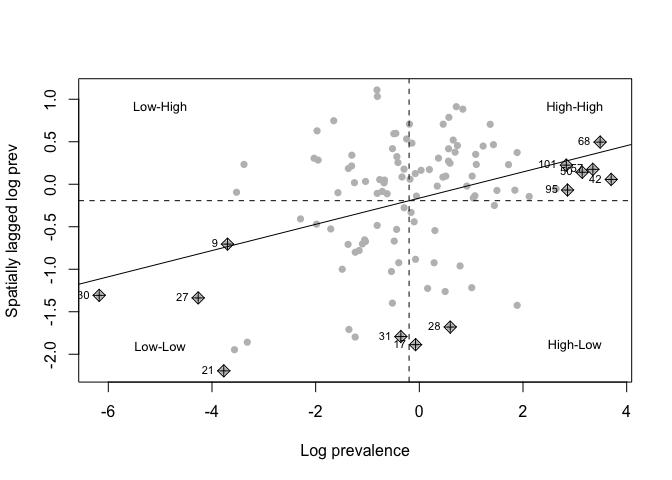
# Map points that are local outliers in the plot
infl<-nci$is_inf==T # find which points are statistically significant outliers
sum(infl==T) #13 true (12% - more than would expect by chance)
## [1] 13
x<-BF_malaria_data$log_odds
lhx<-cut(x, breaks=c(min(x), mean(x), max(x)), labels=c("L", "H"), include.lowest=T)
wx<-lag(weights,BF_malaria_data$log_odds)
lhwx<-cut(wx, breaks=c(min(wx), mean(wx), max(wx)), labels=c("L", "H"), include.lowest=T)
lhlh<-interaction(lhx,lhwx,infl,drop=T)
names<-rep("none", length(lhlh))
names[lhlh=="L.L.TRUE"]<-"LL"
names[lhlh=="H.L.TRUE"]<-"HL"
names[lhlh=="L.H.TRUE"]<-"LH"
names[lhlh=="H.H.TRUE"]<-"HH"
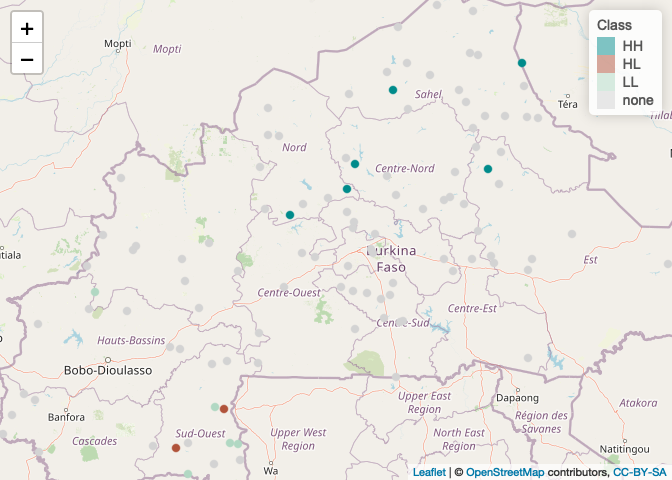
We can map the points to show the local clusters.
BF_malaria_localM<-as.data.frame(cbind(xy,names))
colnames(BF_malaria_localM)<-c("longitude", "latitude", "names")
BF_malaria_localM[c("longitude", "latitude")] <- lapply( BF_malaria_localM[c("longitude", "latitude")], function(x) as.numeric(as.character(x)) )
factpal <- colorFactor(c( "cyan4","coral4","coral","cyan","lightgrey"), names)
leaflet(BF_malaria_localM) %>% addTiles() %>% addCircleMarkers(~longitude, ~latitude, fillOpacity=1,
color= ~factpal(names), radius=4, stroke=TRUE, weight=1) %>%
addLegend(pal = factpal, values = ~names, title="Class")
Part II: Examining spatial point processes
In this section we’re going to look at a different type of point data, point process data, and some of the tests we can use to examine spatial autocorrelation in these data.
First we are going to load obfuscated malaria case data from northern Namibia.
CaseControl<-read.csv("https://raw.githubusercontent.com/HughSt/HughSt.github.io/master/course_materials/week3/Lab_files/CaseControl.csv")
# boundary file
NAM_Adm0<-raster::getData('GADM',country='NAM',level=0)
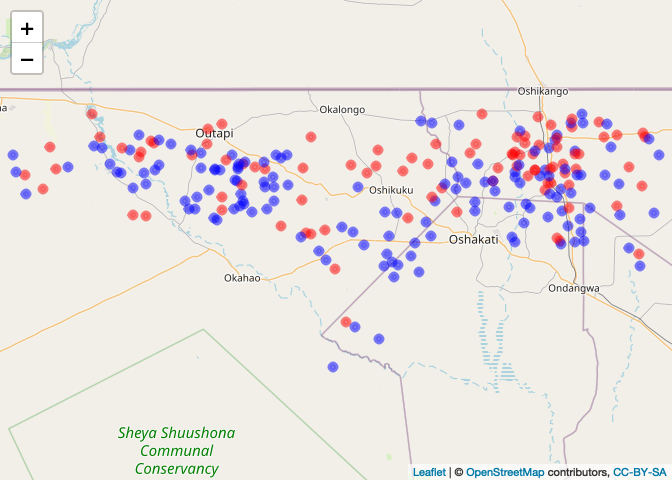
We can convert the data to a SPDF and plot the cases and ‘controls’
CaseControl_SPDF <- SpatialPointsDataFrame(coords = CaseControl[,c("long", "lat")],
data = CaseControl[,c("household_id", "case")])
cases<-CaseControl_SPDF[CaseControl$case==1,]
controls<-CaseControl_SPDF[CaseControl$case==0,]
# Let's plot and see what we have
case_color_scheme <- colorNumeric(c("blue", "red"), CaseControl_SPDF$case)
leaflet() %>% addTiles() %>% addCircleMarkers(data=CaseControl_SPDF, color = case_color_scheme(CaseControl_SPDF$case),
radius=3)
In the previous lecture, you already generated first order kernel density estimates and calculated the ratio of the density estimate of cases:controls. Now you will look at second order functions, summarizing the spatial dependence between events
We need to change the case data to a PPP data type (‘point pattern’)
CasesPPP<-as(cases, "ppp")
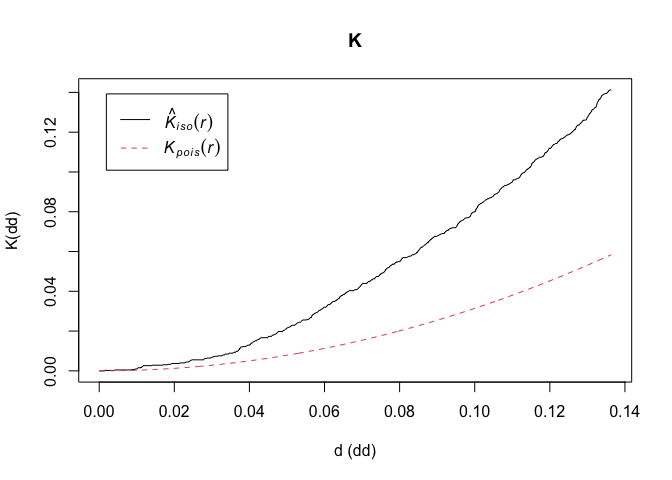
We use Ripley’s K function to summarize the spatial dependence between events at a wide range of spatial scales
K<-Kest(CasesPPP,correction=c("isotropic", "Ripley")) #uses the "spatstat" package
par(mfrow=c(1,1)) # Plot the estimate of K(r); note different border-corrected estimates ('iso', 'border' and 'trans')
plot(K, xlab="d (dd)", ylab="K(dd)") # Red dashed line is expected K value computed for a CRS process
E<-envelope(CasesPPP, Kest, nsim=999) # Plot confidence envelope using MC simulation
plot(E)
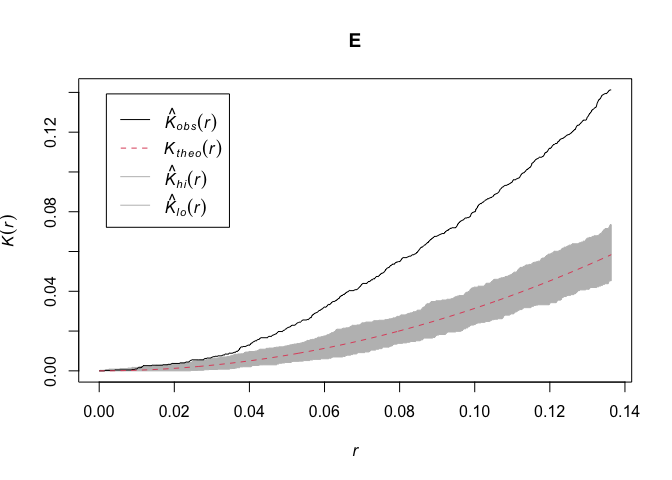
The K-function computed for cases assumes that H0 is complete spatial randomness. What are the limitations of this assumption?
Next we can look at the difference in Ripley’s K function between cases and controls, using two approaches that do essentially the same thing; #2 with hypothesis testing.
Approach 1: K function vignette from Bradley et al simply calculates the K function for cases and controls, and evaluates the difference.
First create a marked point process.
CaseControlPPP<-ppp(CaseControl$long, CaseControl$lat, range(CaseControl$long), range(CaseControl$lat), marks = as.factor(CaseControl$case))
# Calculate the K-function for cases
KX <- Kest(CaseControlPPP[CaseControlPPP$marks==1],correction=c("isotropic", "Ripley"))
plot(KX, sqrt(iso/pi) ~ r)
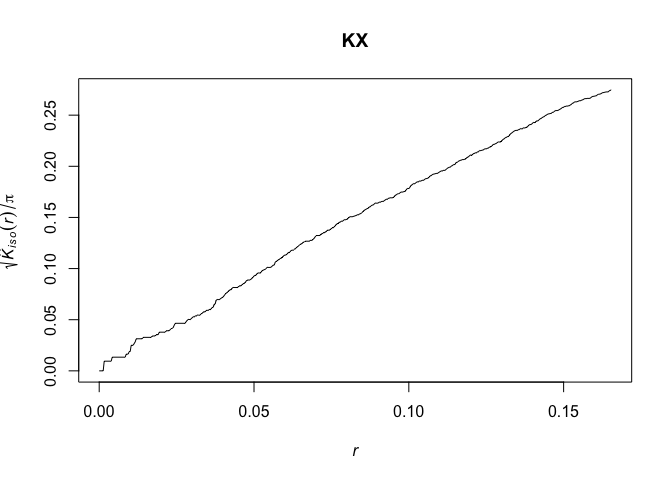
# Calculate the K-function for controls
KY <- Kest(CaseControlPPP[CaseControlPPP$marks==0],correction=c("isotropic", "Ripley"))
plot(KY, sqrt(iso/pi) ~ r)
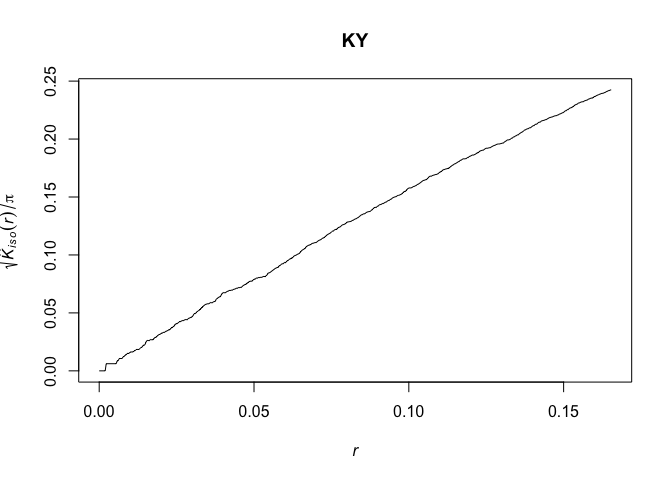
# Calulate the difference in the two functions
Kdiff <- eval.fv(KX - KY)
plot(Kdiff, legendpos="float")
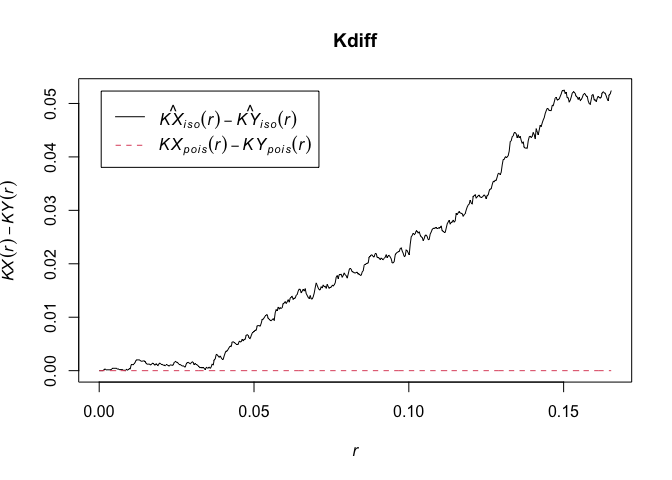
Approach 2: “Smacpod” package includes a function to estimate the difference in K function and plot simulated CI. Also includes a function to the test the significance based on these simulations.
kdest = kdest(CaseControlPPP, case = 2,nsim=999, level=0.95, correction=c("isotropic", "Ripley")) #"smacpod" package
# Note that the case = is position of the marks, not the value! levels(CaseControlPPP$marks)
plot(kdest) # dark grey is min/max; light grey is confidence envelope (can change these with options)
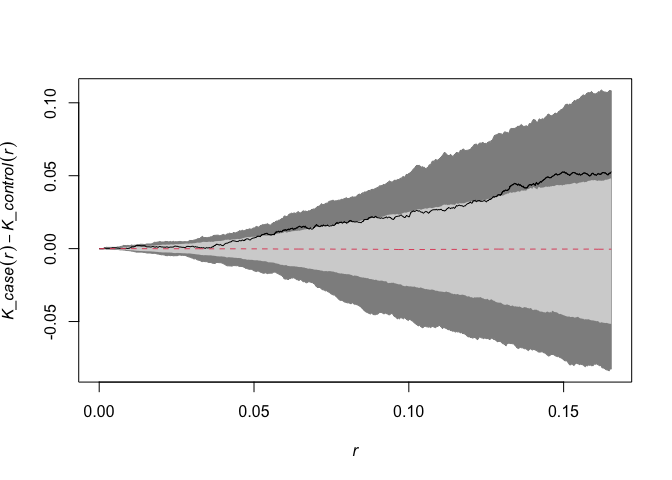
kdplus.test(kdest) # Performs test of significance based on simulated confidence envelope and observed statistic
## The p-value for the global test is 0.024
Spatial Scan Statistics
Finally we will look at spatial scan statistics using R.
On your own, you can also explore using SatScan, a free software tool for spatial scan statistics that you can find here and download: http://www.satscan.org/
For this exercise, we will use the “smacpod” library in R to run the Kulldorf spatial scan statistic.
# Convert CaseControl to a "PPP" object for spatial scan
CaseControlPPP<-ppp(CaseControl$long, CaseControl$lat, range(CaseControl$long), range(CaseControl$lat), marks = as.factor(CaseControl$case))
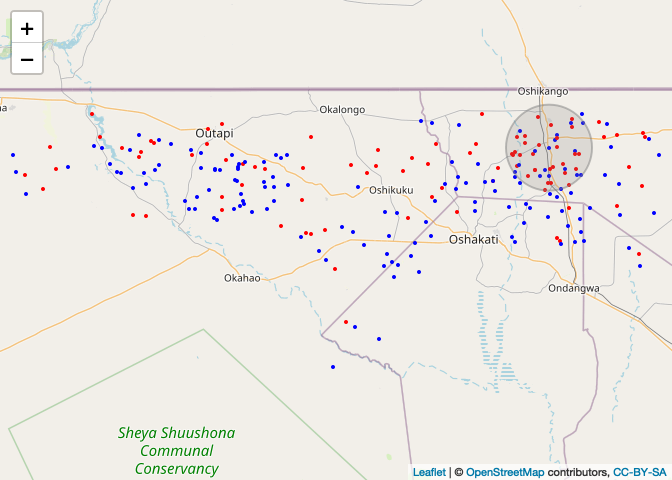
out<-spscan.test(CaseControlPPP, nsim = 999, case = 2, maxd=.15, alpha = 0.05) # "smacpod" library
plot(CaseControlPPP)
case_color_scheme <- colorNumeric(c("blue", "red"), CaseControl_SPDF$case)
leaflet() %>% addTiles() %>% addCircleMarkers(data=CaseControl_SPDF, color = case_color_scheme(CaseControl_SPDF$case),
stroke = FALSE, radius=2, fillOpacity=1)%>%
addCircles(lng = out$clusters[[1]]$coords[,1], lat = out$clusters[[1]]$coords[,2], weight = 2,
radius = out$clusters[[1]]$r*112*1000, color="grey")
Key Readings
Pullan, R. L., H. J. Sturrock, et al. (2012). “Spatial parasite ecology and epidemiology: a review of methods and applications.” Parasitology 139(14): 1870-1887.
Pfeiffer DU, Robinson TP, Stevenson M, Stevens KB, Rogers DJ & Clements ACA (2008). Spatial Analysis in Epidemiology. Chapters 4 & 5. Oxford University Press, Oxford, UK.
Citation for the leukemia data
Turnbull, B. W. et al (1990) Monitoring for clusters of disease: application to leukemia incidence in upstate New York American Journal of Epidemiology, 132, 136-143
Other good resources
Waller LA, Gotway CA (2004) Applied Spatial Statistics for Public Health Data. John Wiley & Sons, Hoboken, New Jersey.
- R library rsatscan can be used to run SatScan from R, see also here: https://www.satscan.org/rsatscan/rsatscan.html
Selection of research applications
Bejon, P., T. N. Williams, et al. (2014). “A micro-epidemiological analysis of febrile malaria in Coastal Kenya showing hotspots within hotspots.” Elife 3: e02130.
Brooker S, Clarke S, Njagi JK, Polack S, Mugo B, Estambale B, Muchiri E, Magnussen P & Cox J (2004). Spatial clustering of malaria and associated risk factors during an epidemic in a highland area of western Kenya. Tropical Medicine and International Health 9: 757-766.
Fevre EM, Coleman PG, Odiit M, et al. (2001). The origins of a new Trypanosoma brucei rhodesiense sleeping sickness outbreak in eastern Uganda. Lancet 358: 625-628.
Huillard d’Aignaux J, Cousens SN, Delasnerie-Laupretre N, Brandel JP, Salomon D, Laplanche JL, Hauw JJ & Alperovitch A (2002). Analysis of the geographical distribution of sporadic Creutzfeldt-Jakob disease in France between 1992 and 1998. International Journal of Epidemiology 31: 490-495.
Gaudart J, Poudiougou B, Dicko A, et al. (2006). Space-time clustering of childhood malaria at the household level: a dynamic cohort in a Mali village. BMC Public Health 6: 286.
Kulldorff M, Athas WF, Feuer EJ, Miller BA & Key CR (1998). Evaluating cluster alarms: A Space-Time Scan Statistic and Brain Cancer in Los Alamos, New Mexico. American Journal of Public Health 88, 1377-1380.
Kulldorff M & Nagarwalla N (1995). Spatial disease clusters: Detection and inference. Statistics in Medicine 14, 799-819. Odoi A, Martin SW, Michel P, et al. (2004). Investigation of clusters of giardiasis using GIS and a spatial scan statistic. Int J Health Geogr 3: 11.
Mosha, J. F., H. J. Sturrock, et al. (2014). “Hot spot or not: a comparison of spatial statistical methods to predict prospective malaria infections.” Malar J 13: 53.
Ngowi HA, Kassuku AA, Carabin H, et al. (2010). Spatial clustering of porcine cysticercosis in Mbulu district, northern Tanzania. PLoS Negl Trop Dis 4: e652.
Peterson I, Borrell LN, El-Sadr W, et al. (2009). A temporal-spatial analysis of malaria transmission in Adama, Ethiopia. Am J Trop Med Hyg 81: 944-949.
Sissoko, M. S., L. L. van den Hoogen, et al. (2015). “Spatial Patterns of Plasmodium falciparum Clinical Incidence, Asymptomatic Parasite Carriage and Anopheles Density in Two Villages in Mali.” Am J Trop Med Hyg 93(4): 790-797.
Washington CH, Radday J, Streit TG, et al. (2004). Spatial clustering of filarial transmission before and after a Mass Drug Administration in a setting of low infection prevalence. Filaria J 3: 3.